Abstract
In-hand manipulation of pen-like objects is an important skill in our daily lives, as many tools such as hammers and screwdrivers are similarly shaped. However, current learning-based methods struggle with this task due to a lack of high-quality demonstrations and the significant gap between simulation and the real world. In this work, we push the boundaries of learning-based in-hand manipulation systems by demonstrating the capability to spin pen-like objects. We first use reinforcement learning to train an oracle policy with privileged information and generate a high-fidelity trajectory dataset in simulation. This serves two purposes: 1) pre-training a sensorimotor policy in simulation; 2) conducting open-loop trajectory replay in the real world. We then fine-tune the sensorimotor policy using these real-world trajectories to adapt it to the real world dynamics. With less than 50 trajectories, our policy learns to rotate more than ten pen-like objects with different physical properties for multiple revolutions. We present a comprehensive analysis of our design choices and share the lessons learned during development.
Real-world Results
Sim-to-Real does not work for Pen Spinning
Despite the great progress in sim-to-real for in-hand manipulation, we find that it does not directly apply to our task due to the large sim-to-real gap. While this gap generally exists in previous work, the extreme difficulty of spinning pen-like objects exacerbates it further. Although we did extensive exploration and iterations on hardware design, object selection, and different input modalities, we have not achieved any success. The object is always easily dropped or even completely fails due to the distribution shift.
How did we achieve this?
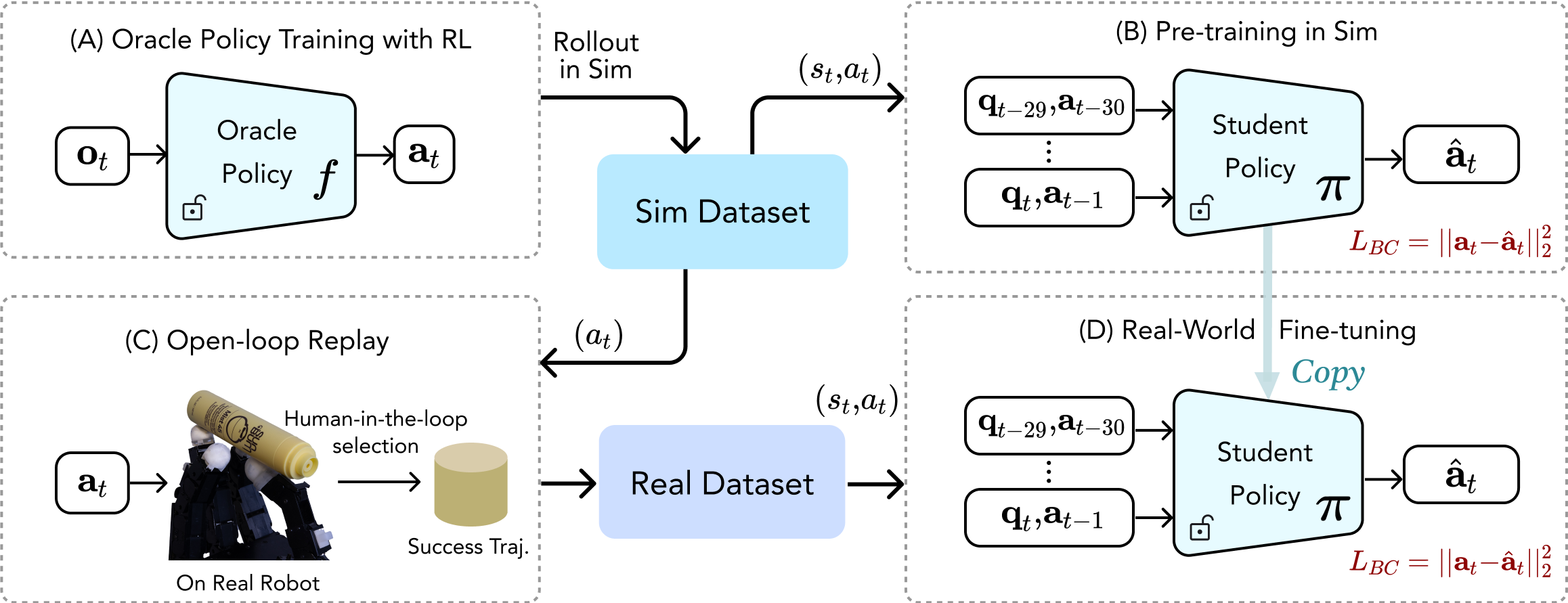
An overview of our approach. We first train an oracle policy in simulation using reinforcement learning. This policy provides high-quality trajectory and action datasets. We use this dataset to train a student policy and as an open-loop controller in the real world to collect successful real-world trajectories. Finally, we fine-tune the student policy using this real-world dataset.
Qualitative Comparison for Oracle Policy
Our Method.
Emergent Fingergaiting.Continuous Spinning.
Single Canonical Pose
No Fingergaiting.Inefficient exploration.
Without Z-reward
Objects tilted in certain timesteps.Easily slip in the real-world.
Failure Cases (Baselines)
Open-loop Replay
The motion is reasonable but not reactive and generalizable enough.Simulation Pre-training Only
Not able to finish the task since the large sim-to-real gap.Vision Distillation
Object oscillates resulting in large OOD error for vision systems.Failure Cases (Our Method)
Lessons Learned
- Simulation training requires extensive design for exploration, such as the proper design of initial distributions to aid exploration and using privileged information to facilitate policy learning.
- Sim-to-Real does not directly work for such contact-rich and highly dynamic tasks. Even when isolating touch and vision, the pure physics sim-to-real gap remains significant and cannot be bridged by extensive domain randomization alone.
- Simulation is still useful for exploring skills. The dynamic skill of spinning pens with a robotic hand is nearly impossible to achieve with human teleoperation and imitation learning alone. Reinforcement learning in simulation is critical for exploring feasible motion.
- Only a few real-world trajectories are needed for fine-tuning. Although a proprioceptive policy learned purely in simulation does not work directly in the real world, it can be fine-tuned to adapt to real-world physics using only a few successful trajectories.
Bibtex
@inproceedings{wang2024penspin,
author={Wang, Jun and Yuan, Ying and Che, Haichuan and Qi, Haozhi and Ma, Yi and Malik, Jitendra and Wang, Xiaolong},
title={Lessons from Learning to Spin “Pens”},
booktitle={CoRL},
year={2024}
}
Acknowledgement
The simulation visualization in paper are created by Viser.
Xiaolong Wang’s lab is supported, in part, by Amazon Research Award, Intel Rising Star Faculty Award, Qualcomm Innovation Fellowship, and gifts from Meta. Haozhi Qi and Jitendra Malik are supported in part by ONR MURI N0001421-1-2801. Haozhi Qi and Yi Ma are supported in part by ONR N00014-22-1-2102.